Your Music Has No Genre: Reading It Off the Waveform
Serendeep Rudraraju

I wanted my Spotify playlists as local files, sorted into a tree my DJ software can read: genre on the outside, tempo band on the inside, hard techno/140-147/. A gig set or a workout mix as something I own, not something I rent from a stream. The tempo was a solved problem. The genre turned out not to exist — not in the file, not in any database I could reach.
spotdl pulls a playlist down as audio. librosa computes tempo. Nobody joins download → analyze → sort into one pass, but that's plumbing, and I'll cover the plumbing in Part 2. The part that wasn't plumbing, and the part that ate the week, was that the music I actually listen to has its genre written down nowhere. Fixing that ended with an audio transformer running on my laptop, listening to each track and telling me it's hard techno. This is the story of that half.
TL;DR
Spotify cut the BPM API for new apps in late 2024, so tempo has to be computed locally. The genre is the hard part: underground electronic ships with no genre tag, and every metadata source I tested came back empty, wrong, or too coarse to be useful. The genre is in the audio, though, so I run a small ONNX model (MAEST, 400 Discogs styles, ~330 MB, on the CPU) that reads the sub-genre straight off the waveform — no account, no upload. The bug worth writing down: the model labelled every techno track as "Cumbia" or "Chanson" until I reproduced its mel-spectrogram front end to the byte. ML preprocessing fails silently. This is Part 1 of two; Part 2 covers tempo, key, and the download plumbing.
One half of the job was solved in 2024. The other half was never solved at all.
Until late 2024, you didn't compute any of this. You asked Spotify. The audio-features endpoint handed you tempo, key, energy, danceability, the lot. Then on November 27, 2024 Spotify deprecated audio-features and audio-analysis for any app without a prior quota extension. New apps get a 403. Eighteen months later there is still no replacement.
So tempo moves in-house: you load the audio and run librosa.beat.beat_track, then fold the inevitable half/double octave errors back into a sane window. It's a known computation, and it's the first thing Part 2 picks up. The genre has no equivalent. There is no endpoint, no librosa one-liner, and as it turns out, no database either.
The genre is not in any database
Here is the part nobody warns you about: for underground electronic, genre metadata barely exists.
spotdl writes whatever Spotify has into the file tags. For a T78 or a Timmo or a Clara Cuvé track, the genre field comes back empty. Spotify knows the artist, the album, the release date. It does not know the genre of the individual track. So I reached for MusicBrainz, the open music database, the obvious next stop. I pulled eight of my own tracks and looked each up by hand. Four returned empty genre and tag lists. Four had no match at all. MusicBrainz is a good project, but it was built by people cataloguing the music they care about, and nobody has sat down to tag last month's hard-groove white label.
I was convinced for about a day that the answer was a better lookup. There is a whole chain of them, so I tested each against my real tracks rather than against the docs:
| Source | Credential | What it actually returned |
|---|---|---|
| Embedded tag (spotdl/Spotify) | none | empty for every track |
| MusicBrainz | none | 4/8 empty, 4/8 no match |
| Last.fm tags | free key | matched the wrong artist on a Unicode lookalike; otherwise generic ("edm") |
| Deezer | none | matched 17/18, but everything is "Electro" or "Dance" — no sub-genre |
| Discogs styles | token | genuinely good ("Peak Time / Driving"), but misses the newest releases |
Every row has the same flaw. Each depends on someone, somewhere, having already written the genre down. Deezer matches almost everything and tells me nothing, because its taxonomy can't separate hard techno from tech house. Discogs is the closest to right and still misses exactly the recent underground releases I care about. For new music, the authoritative label doesn't exist yet, so no lookup can return it.
That was the reframe that mattered: I didn't have a lookup problem. I had a label that only existed in the audio.
So compute the label from the signal
A DJ can hear four bars and name the sub-genre. The information is in the waveform; it simply isn't in any text field. Which turns the problem from "find a better database" into "classify the audio," and there is a model for that.
MAEST is an audio transformer, about 86M parameters, built on the Audio Spectrogram Transformer line and trained on 400 Discogs styles. You feed it audio, it returns probabilities over a taxonomy that natively separates Hard Techno, Tech House, Minimal Techno, and Trance. cratemind runs the discogs-maest-10s-pw-1 ONNX export on onnxruntime on the CPU. The model is optional and downloaded on first use (about 330 MB, fetched from the Essentia model host into a local cache), and the whole classifier is written so any failure returns None and the resolver falls back gracefully:
# src/cratemind/genre/audio.pydef is_available() -> bool: """True when the model is downloaded and onnxruntime is importable.""" if not model_path().exists() or not metadata_path().exists(): return False try: import onnxruntime # noqa: F401 except ImportError: return False return Truedef lookup_audio_genre(path: Path) -> str | None: """Predict a raw sub-genre label (e.g. "Hard Techno"), or None if unsure.""" if not is_available(): return None try: scores = _predict(path) if scores is None: return None best = int(scores.argmax()) if scores[best] < _MIN_CONFIDENCE: # 0.10 — below this it's guessing return None return _clean_label(_labels()[best]) except Exception: return NoneNo account, no API, no cloud round-trip. The model file sits in a cache directory and the audio never leaves the machine. For a tool whose whole premise is "this is local and it's yours," that mattered more than a point or two of accuracy.
The cost is honesty about size. I went for the lighter 18 MB variant first, and it ships its classifier head as a TensorFlow graph with no ONNX export, which would have pulled TensorFlow back into a project working hard to avoid it. The larger self-contained model is 330 MB and end-to-end ONNX. One download, then it runs offline forever. I took the disk over the dependency.
The recipe has to match to the byte
Here is the thing about lookup_audio_genre that took me a week to get right: MAEST doesn't take audio. It takes a mel-spectrogram, a specific 2D representation, and that spectrogram has to be computed with the exact recipe the model trained on. Not a reasonable mel-spectrogram. That one. The constants are part of the model.
# src/cratemind/genre/audio.py — _patches(), trimmedpower = ( np.abs(librosa.stft(samples, n_fft=512, hop_length=256, win_length=512, window="hann")) ** 2 # power spectrogram (power=2), NOT magnitude)mel = np.maximum(_mel_filter() @ power, 1e-30) # 96 slaney mel bands, mel_floorlog_mel = np.log10(1.0 + 10000.0 * mel).T.astype(np.float32)log_mel = (log_mel - 2.06755686098554) / (1.268292820667291 * 2.0) # Discogs20 normEvery line there is a place I was originally wrong. The mel filter is the slaney scale with slaney normalization, at 16 kHz with 96 bands. The spectrogram is power, not magnitude. The log step isn't power_to_db; it's log10(1 + 10000·mel), an Essentia-specific compression. And the final line subtracts the training-set mean and divides by twice the standard deviation — two constants, 2.06755686098554 and 1.268292820667291, that are as much part of the model as any weight. The audio is then chunked into 626-frame patches (the model's fixed time dimension, ~10 s), capped at six patches per track so a long mix doesn't trigger dozens of inferences, and the per-patch probabilities are averaged.
There's also a runtime trap worth one line. Ask the ONNX session for everything and you get noise:
# Ask only for the class head. Requesting None returns all 14 outputs,# including 12 unused per-layer token tensors whose model-declared rank-1# shape mismatches their rank-3 runtime shape, spamming onnxruntime warnings.outputs = session.run(["logits"], {input_name: patches})The bug: confidently wrong, and silent about it
The first run was garbage, delivered with total confidence. T78's "Bombacid," a peak-time techno track, came back as Grime. Timmo's "Salty" came back as Cumbia. Clara Cuvé got Chanson. The model wasn't broken. It was being handed nonsense and answering the question it was actually asked.
The two errors were the ones in the snippet above: I'd used the magnitude spectrum where the model expects power, and I'd skipped the per-dataset normalization entirely. To the model, my input wasn't quiet techno or loud techno. It was off the manifold the network had ever seen, so it landed wherever. Fixing it meant reproducing the published feature extractor exactly — power spectrogram, slaney mel, the log10(1 + 10000·mel) compression, the two normalization constants. Same audio, same model, corrected input:
| Track | Before | After |
|---|---|---|
| Luciid — Era Of Us | Drum n Bass | hard techno (0.78) |
| OMAKS — On Da Beat | Hardcore | hard techno (0.62) |
| Timmo — Salty | Cumbia | techno (0.60) |
| Lorenzo Raganzini — Born Slippy | Hardcore | hard techno (0.43) |
Fourteen of eighteen landed on a correct hard-electronic sub-genre. The remaining four sit at low confidence, which is exactly where you want your errors: below the 0.10 floor, where they fall through to the next option instead of asserting nonsense.
The transferable lesson is the silence. A misconfigured preprocessor doesn't raise. The model doesn't report that its input is out of distribution. It returns a clean, well-formed, completely wrong answer, and if you don't have ground truth to check against (say, eighteen tracks you happen to know the genre of), you ship it. With models, the failure that costs you is rarely a crash. It's a confident answer to a question you didn't realize you were asking.
Never strand a file
A sorting tool has one unforgivable bug: losing a track. So genre resolution isn't a single lookup, it's a chain that always lands somewhere. The code reads top to bottom as "most specific source first, then degrade":
# src/cratemind/genre/resolve.py — resolve_genre(), trimmedtagged = canonicalize(track.genre, aliases) # 1. embedded tagif tagged: return taggedif audio_genre_lookup and track.file_path: # 2. the MAEST model from_audio = canonicalize(audio_genre_lookup(track.file_path), aliases) if from_audio: return from_audioif artist_genre_lookup: # 3. artist-genre hook from_artist = canonicalize(artist_genre_lookup(track.artist), aliases) if from_artist: return from_artistif coarse_genre_lookup: # 4. coarse Deezer (opt-in) coarse = canonicalize(coarse_genre_lookup(track.artist, track.title), aliases) if coarse: return coarsereturn (track.artist or "").strip() or None # 5. file under the artistEmbedded tag first if it exists, then the audio model, then an artist-level lookup, then a coarse Deezer query by name, and that fourth step is the only one that leaves your machine, so it's off unless you opt in. If everything comes up empty, the track is filed under the artist's name rather than dropped in an "unsorted" bucket. An artist folder is a real location. "Unsorted" is where files go to be forgotten.
Two small details make this hold together. Every candidate runs through canonicalize, which lowercases, expands & to and, collapses whitespace, and applies an alias map (dnb → drum and bass, edm → electronic). Without it, "Drum & Bass" from one source and "drum and bass" from another become two folders for the same music. And the artist name is returned verbatim (T78, not t78) because a folder is a label a human reads.
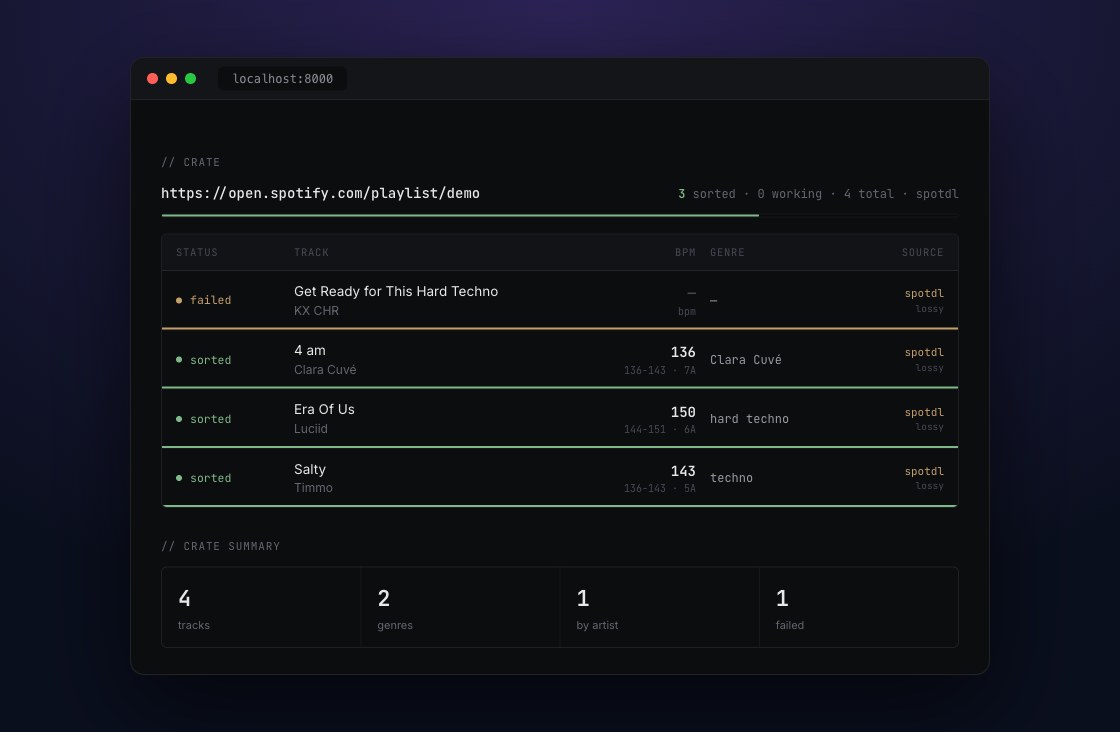
You can see the whole chain resolve in one screenshot. Three tracks sorted by audio, one (Clara Cuvé) with no resolvable genre filed under the artist, and a download that failed surfaced as a yellow row at the top instead of silently missing:
Where this leaves you
It began as "download my playlists" and turned into a small argument I didn't expect to be making: for the music worth digging for, the metadata was never going to save you. The label isn't in the database. It's in the signal, and you have to compute it.
If you're building something adjacent (a media sorter, a tagger, anything that leans on a model), five things this taught me:
- Don't re-derive what's deprecated, recompute it. Spotify's audio API is gone for new apps; the data is still in the file, waiting to be measured.
- When the lookup keeps failing, ask whether the label exists at all. For new or niche data, no database can return a label nobody has written down yet. Move the problem out of the database and into the signal.
- Reproduce a model's preprocessing to the byte, not approximately. Power versus magnitude and one skipped normalization were enough to send every input off-distribution. The published feature extractor is the spec; match it exactly, constants and all.
- Keep ground truth within reach. A handful of examples you already know the answer to is the only thing that catches a confidently-wrong model. Eighteen tracks saved this project.
- Make failures loud. Always land a file somewhere real, and surface a missing result instead of a silently shorter list. The bug you can't see is the one that ships.
That last point, making failures loud, plus the tempo and key work I waved at up top, is the other half of the tool. Part 2, The Rest of the Crate, covers the librosa octave-fold, Camelot key detection, embedding the analysis where DJ software reads it, the download diff that surfaces every failed track, and the crate.json you can hand to a friend. The tool itself is cratemind on GitHub, and everything in both posts runs on your machine.
The label isn't in the database. It's in the signal, and you have to compute it.
Sources
- Spotify cuts developer access to several of its Web API features — the Nov 27, 2024 deprecation of
audio-features/audio-analysis - MAEST model card (mtg-upf/discogs-maest-10s-pw-129e) — 400 Discogs styles, mel-spectrogram input, the normalization constants
- MAEST repository (palonso/MAEST) — architecture and ONNX export path
- cratemind
genre/audio.py— the mel front end, the confidence floor, the logits gotcha - cratemind
genre/resolve.py— the five-step resolution chain - librosa — tempo and chroma; the local audio stack
- spotDL/spotify-downloader — pulls a playlist as audio, writes Spotify's (often empty) tags
- MusicBrainz — the open database that came up empty for new underground releases
- Deezer API — matches nearly everything, returns only coarse genres
- Discogs API — accurate styles, but misses the newest releases
Enjoyed this post? Consider supporting the blog.
Buy me a coffee