The Rest of the Crate: Tempo, Key, and Never Stranding a File
Serendeep Rudraraju

Part 1 was the interesting problem: the genre that lived nowhere except in the audio, and the silent ML bug that came with computing it. This is the boring 80% that decides whether the tool is actually usable. The tempo that lies to you by a whole octave. The musical key, which turns out to need 1990s music theory and no model at all. The tag fields that DJ software actually reads. And a downloader that must never, ever quietly lose a track.
None of it is clever. All of it is load-bearing. The screenshot from Part 1 only looks clean because each of these pieces holds, and tools mostly die in exactly this layer — not in the headline feature, but in the plumbing under it.
TL;DR
cratemind computes tempo with librosa and folds the octave errors into a sane window; detects musical key with the Krumhansl–Schmuckler profiles and writes it in Camelot notation for harmonic mixing; embeds key/BPM/genre into each file's native tags via mutagen so Rekordbox and Mixxx can see them; surfaces every failed download by diffing the expected tracklist against what actually arrived; and ships a portable crate.json that carries the analysis but never the audio. The whole thing is unit-testable without librosa or the network, because every heavy dependency is injected and the settings object is immutable. This is Part 2 of two.
Tempo lies by an octave
A beat tracker doesn't return the tempo. It returns a tempo, a beat grid that fits the audio, and half-time is always a valid grid. So librosa.beat.beat_track will happily report a 140 BPM track as 70, and a 124 BPM house track as 62. Run a playlist through it raw and your tracks scatter across two tempo bands that are exactly an octave apart.
The fix is to decide what range real dance music lives in and fold everything into it by doubling or halving. It's a handful of lines, it's pure, and it's the part that's actually unit-tested. The librosa call that produces the raw number is a thin wrapper, imported lazily:
python# src/cratemind/analysis/bpm.pydef fold_octave(bpm: float, low: int, high: int) -> int: """Fold a tempo into [low, high] by doubling/halving, then round.""" value = float(bpm) while value < low: value *= 2 while value > high: value /= 2 return round(value)def bucket(bpm: int, width: int) -> str: """Name the fixed-width band a tempo falls in, e.g. bucket(105, 8) -> '104-111'.""" start = (bpm // width) * width return f"{start}-{start + width - 1}"
cratemind's defaults are a 70–180 BPM window and 8 BPM buckets, both in the settings object. The bucket is what becomes the {bpm_bucket} folder (136-143/), so harmonically and rhythmically adjacent tracks end up shelved together. A 124 track files under 120-127, never under 56-63, because the octave got folded before the bucket got named.
The key is older than the model
Genre needed an 86M-parameter transformer. Key needs a correlation and two vectors from 1990.
The Krumhansl–Schmuckler method is simple enough to state in a sentence: build a 12-bin histogram of how much energy each pitch class carries, then correlate it against an idealized profile for every possible key and pick the best fit. The profiles are empirical: Carol Krumhansl measured how strongly listeners felt each note belonged in a given key, and they're just twelve numbers each for major and minor. librosa.feature.chroma_cqt gives you the histogram; the rest is arithmetic over the 24 candidate keys:
python# src/cratemind/analysis/key.py — camelot_from_chroma(), trimmedbest_tonic, best_mode, best_corr = 0, "maj", float("-inf")for tonic in range(12): rotated = vec[tonic:] + vec[:tonic] # align this candidate tonic to index 0 for mode, profile in (("maj", _MAJOR), ("min", _MINOR)): score = _corr(rotated, profile) # Pearson correlation if score > best_corr: best_tonic, best_mode, best_corr = tonic, mode, scorereturn CAMELOT_MAJOR[best_tonic] if best_mode == "maj" else CAMELOT_MINOR[best_tonic]
The output isn't F# minor, it's 11A — Camelot notation. The Camelot wheel is a DJ's relabeling of the circle of fifths: every key gets a number 1–12 and a letter (A for minor, B for major). Two tracks mix harmonically if their codes are equal, one number apart, or share the number across the A/B boundary. Putting 8A in the tag instead of A minor means the number itself tells you what mixes, which is the entire point of detecting key for a DJ set. cratemind keeps the pitch-class-to-Camelot maps as plain dictionaries, and converts back to musical notation (Am) for tools like Mixxx that expect that in the key field.
Sorting isn't enough: DJ software reads tags
Here's a mistake I made early: I sorted everything into beautiful {genre}/{bpm_bucket}/ folders and assumed I was done. Then I imported a folder into Rekordbox and every BPM and key column was blank. DJ software doesn't read your directory structure. It reads the metadata embedded in each file, and a freshly downloaded track has none of it.
So the analysis has to be written back into the files, and every container format stores tags differently. FLAC uses Vorbis comments, MP3 uses ID3 frames, M4A uses MP4 atoms. cratemind has a small dispatch per format:
python# src/cratemind/download/write_tags.pydef _apply_vorbis(tags, key_value, bpm, genre): # FLAC if key_value: tags["INITIALKEY"] = key_value if bpm: tags["BPM"] = str(bpm) if genre: tags["GENRE"] = genredef _apply_id3(tags, key_value, bpm, genre): # MP3 from mutagen.id3 import TBPM, TCON, TKEY if key_value: tags.setall("TKEY", [TKEY(encoding=3, text=key_value)]) if bpm: tags.setall("TBPM", [TBPM(encoding=3, text=str(bpm))]) if genre: tags.setall("TCON", [TCON(encoding=3, text=genre)])def _apply_mp4(tags, key_value, bpm, genre): # M4A from mutagen.mp4 import MP4FreeForm if key_value: tags["----:com.apple.iTunes:initialkey"] = [MP4FreeForm(key_value.encode())] if bpm: tags["tmpo"] = [int(bpm)] if genre: tags["©gen"] = [genre]
| Format | Key field | BPM field | Genre field |
|---|---|---|---|
| FLAC (Vorbis) | INITIALKEY | BPM | GENRE |
| MP3 (ID3v2) | TKEY | TBPM | TCON |
| M4A (MP4) | ----:…:initialkey | tmpo | ©gen |
Two decisions matter here. The key is written as the Camelot code by default because that's what most DJ software reads, with a musical option for Mixxx. And the whole operation is best-effort: the entire write_tags body is wrapped so that any failure is swallowed. A sorted file with no embedded tags is still a sorted file, and I would rather lose a tag than fail a sort over a mutagen edge case.
Never strand a file
A sorting tool has one unforgivable bug: losing a track. The genre chain in Part 1 was the same instinct applied to labels: always land somewhere. This is the same instinct applied to downloads.
The trap is that a downloader failing partway looks exactly like success. spotdl couldn't match three songs, the files never appear, and the interface shows 47 tracks instead of 50 with no error. Nobody notices until they're in the booth missing the one track they queued the set around.
cratemind closes that by knowing what should have arrived before it starts. spotdl save writes the full resolved tracklist to a file first (metadata only, no audio), which doubles as the live progress denominator. After the download, it diffs the expected tracklist against the files that actually landed, matched by normalized title so a stray artist-string difference doesn't false-flag a real download:
python# src/cratemind/download/backends.pydef _failed_from_expected(save_file, downloaded, source): """Expected songs that have no matching downloaded file, as failed Tracks.""" expected = _expected_tracks(save_file, source) if not expected: return [] got = {normalize_title(t.title) for t in downloaded} return [e for e in expected if normalize_title(e.title) not in got]
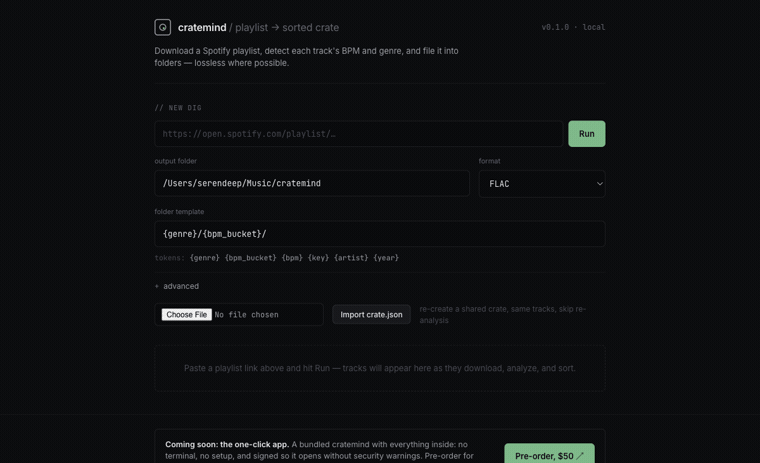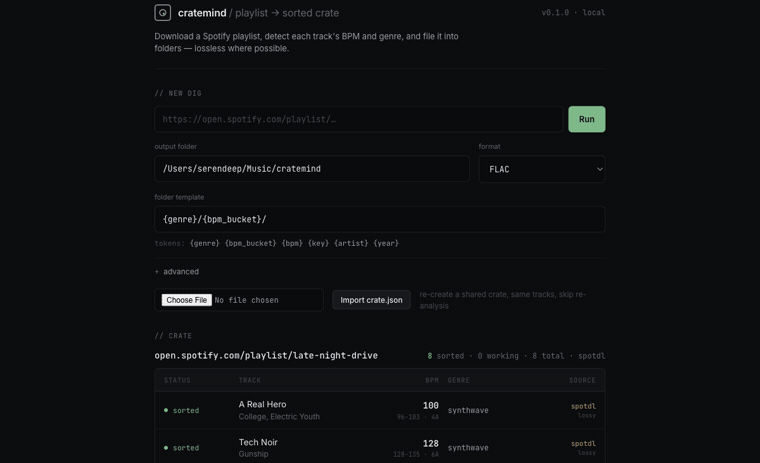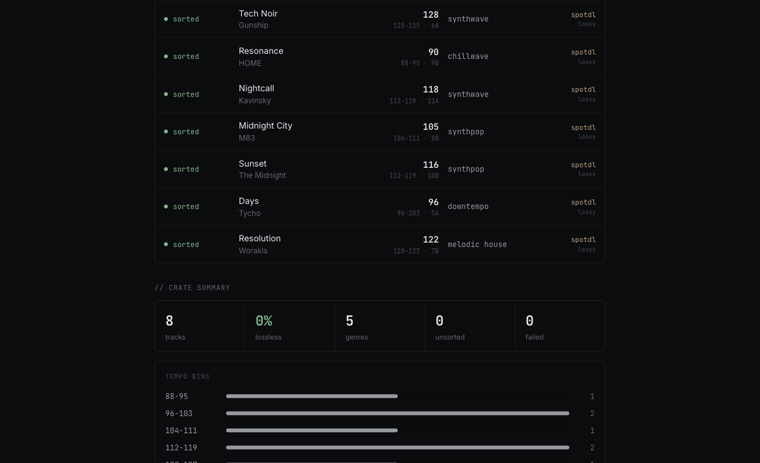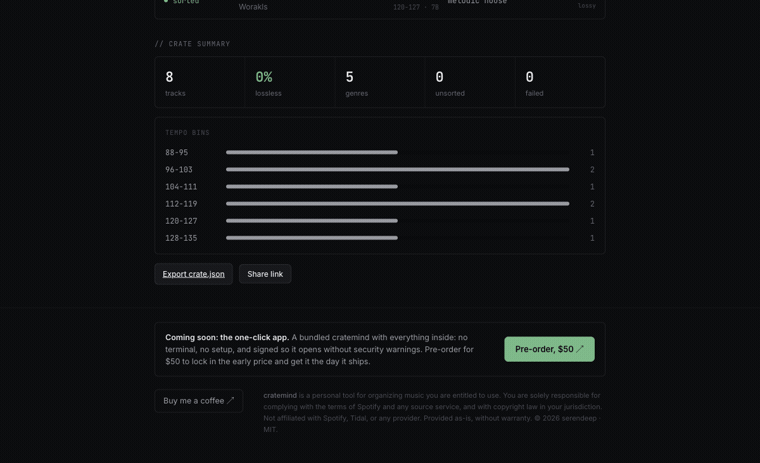
Those failures come back as real Track objects with status="failed", and the runner surfaces them in the UI as rows rather than dropping them. That's the yellow row at the top of the Part 1 screenshot. Two more touches round it out: a run that crashes mid-download still processes whatever files did land instead of orphaning them, and resume is per-track, so a track already marked sorted on a previous run skips re-analysis. (There are two backends behind one interface, by the way: a lossless SpotiFLAC path that's currently paused because its free mirrors are unreliable, and spotdl as the dependable default. Both are external CLIs invoked as subprocesses, not library dependencies.)
Why it's all injectable and immutable
You may have noticed that every code sample so far is a small, pure function. That's not an accident, and it's the thing I'm most quietly proud of. Every external dependency in the pipeline (the tempo estimator, the key estimator, the genre lookups, the tag writer, the downloader) is a parameter with a sensible default:
python# src/cratemind/pipeline.py — process_track signaturedef process_track( track, settings, *, estimator=estimate_raw_bpm, key_estimator=estimate_camelot, audio_genre_lookup=lookup_audio_genre, coarse_genre_lookup=lookup_deezer_genre, tag_writer=write_tags,) -> Track:
In production the defaults run. In tests, you pass fakes, and the entire sort-and-resolve logic gets exercised without librosa, without onnxruntime, without touching the network. That's why the analysis, genre, and organize modules each have a real unit-test file that runs in milliseconds.
The settings object that threads through all of it is a frozen dataclass: updates return a copy via with_(), and even the alias mapping is wrapped in a MappingProxyType so an "immutable" config can't be mutated in place. The heavy imports (librosa, onnxruntime, mutagen, httpx) are all deferred to the function that needs them, so importing cratemind to run a unit test doesn't drag in the audio stack. Small functions, injected dependencies, immutable state — it reads like a coding-standards lecture, but it's the reason the tool is pleasant to change.
A crate you can hand to a friend
The last piece is sharing. I wanted to send someone "my late-night-drive crate" without sending them gigabytes of copyrighted FLAC. The answer is to share the analysis, not the audio.
crate.json is a versioned pydantic manifest. It carries the Spotify ID, title, artist, and the computed genre/BPM/key for each track, and nothing else:
python# src/cratemind/manifest.pyclass TrackEntry(BaseModel): spotify_id: str title: str artist: str genre: str | None = None bpm: int | None = None bpm_bucket: str | None = None key: str | None = Noneclass CrateManifest(BaseModel): version: int = MANIFEST_VERSION playlist_url: str playlist_name: str | None = None tracks: list[TrackEntry] = Field(default_factory=list)
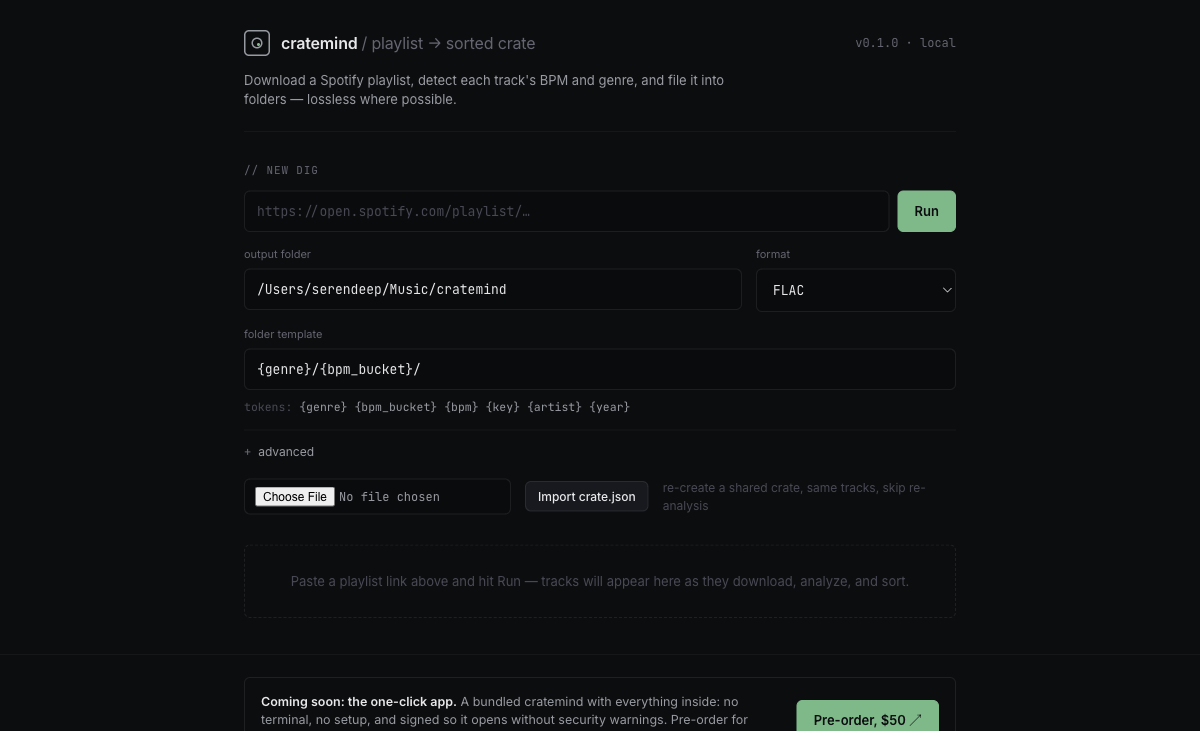
Import one and cratemind re-downloads the same tracks and files them identically, skipping analysis entirely. The BPM and genre come from the manifest, so there's no librosa on the import path at all. It's portable by construction and copyright-clean by construction: the file is data about music, not music. You can see the Import crate.json control on the home screen:
Where this leaves you
The genre model got the headline in Part 1. But the tool lives or dies on this half — the octave fold, the key profiles, the tag fram es, the honest failure row. If you're building anything that analyzes media and writes it somewhere, five things worth stealing:
- Fold tempo octaves before you trust a BPM. A beat tracker returns a valid grid, not the true tempo; pick a window and fold.
- Reach for music theory before a model. Key-finding is a correlation against two empirical vectors, not a training run: instant, dependency-free, good enough.
- Write your analysis where the consumer reads it. Folders are for humans; the consuming software reads file tags. Embed them, per format, best-effort.
- Diff expected against actual. Know what should have arrived before you start, so a shortfall is a visible row and not a silent success.
- Make the heavy dependencies injectable. Default to the real thing, accept a fake, and your logic stays testable without the audio stack or the network.
That's the whole tool: Part 1 computes the genre off the waveform, and this half does the unglamorous work of getting every track measured, tagged, sorted, and never lost. cratemind is on GitHub, and it installs in one line:
bashcurl -fsSL https://raw.githubusercontent.com/Serendeep/cratemind/main/install.sh | sh
Everything runs on your machine. The audio never leaves it.
The interesting problem gets the blog post. The plumbing is what gets used.
Sources
- cratemind
analysis/bpm.py— the octave fold and tempo bucketing - cratemind
analysis/key.py— Krumhansl–Schmuckler key profiles → Camelot - cratemind
download/write_tags.py— per-format tag embedding via mutagen - cratemind
download/backends.py— the expected-vs-received failure diff - cratemind
manifest.py— the versionedcrate.jsonschema - librosa
beat_track— the tempo estimator and its octave behavior - Krumhansl–Schmuckler key-finding — the key-profile correlation method, explained
- mutagen — the audio metadata library doing the tag writing
- Your Music Has No Genre (Part 1) — the genre model and the silent-ML-bug story
Enjoyed this post? Consider supporting the blog.
Buy me a coffee